

Nowadays it is hard to believe that the term Relational Model exists for 52 years. However, it does, indeed. The history of Relational Databases of the XXth century started in June 1970.
In 1970 Edgar Codd, a computer scientist from California published a paper called “A Relational Model of Data Large Shared Data Banks”. The paper introduced the concept of the Relational Model, Normalization, and operations on relations, and covered Data Redundancy and Consistency topics.
In this post, we will review the rationale standing behind the model, go through the related terms, and definitions, and reinforce the foundation upon which our Relational Database knowledge must rest.

The Rational for Relational Data Model
The existing data storage solutions did not cope with the new challenges that appeared in the early 70s due to significant data growth and the requirement for frequent changes in data. The hierarchical (e.g. TDMS, IMS, IDS) and network (e.g. CODASYL) models implied high coupling between the application code and the data structure.
Let’s imagine: you want to insert a new record into a database, but this time you don’t have any contemporary toolset; SQL is not invented yet, and you must programmatically traverse existing indices, taking into account the ordering of the records and other low-level details.
Then, if you decided to implement a bit more complex task like adding a new attribute or introducing a new index, the chances are aside from the database file, you have to rewrite the whole data layer in your application.
It is hard to imagine, isn’t it? We are too spoiled because, in the old days, such tasks were not doable without a proper set of advanced engineering skills.
Edgar F. Codd cared about us and described the following problem:
Future users of large data banks must be protected from having to know how the data is organized in the machine.
Activities of users at terminals and most application programs should remain unaffected when the internal representation of data is changed.
E. F. Codd, “A Relational Model of Data Large Shared Data Banks”
The Relational Data Model as a Flagman of Independence
The relational model eliminated 3 types of dependencies:
- Ordering dependence. In those days, the ordering in the databases was implemented as the physical ordering of the stored elements in a database file. If you wanted to change the ordering, you had to rewrite the file as well as the logic in all the dependent applications.
- Indexing Dependence. Indexing was another pain point:
- TDMS unconditionally indexed all the attributes
- IMS, in turn, allowed you to disable indexing for specific files
- The most advanced approach was proposed by IDS where you could select attributes for indexing into named chains and then refer to these chains in your application by the name. And again, if you changed the name of the chain – you had to rewrite the app.
- Access Path Dependence:
- Tree-based data models forced you to specify the full path to the attribute. If you changed something in the structure, you had to rewrite the paths in your application.
- The network model of the data had similar issues. It provided users with paths for accessing the data and any changes to those paths required changes in the application.
Terms introduced by Mr. Codd
Relations and Relationships
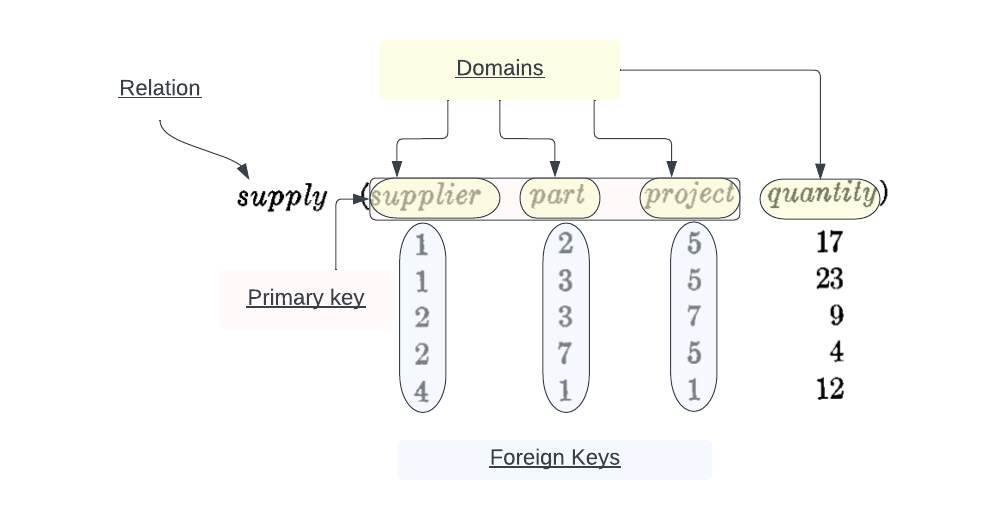
| Term | Definition |
| Relation | Given sets S1, S2, …, Sn (not necessarily distinct) n is a relation of these n sets if it is a set of n tuples each of which has its first element from S1, its second element from S2, and so on. |
| Relationship | We propose that users deal not with relations that are domain-ordered, but with relationships that are their domain-unordered counterparts |
| Primary key | A domain (or a combination of domains) in a given relation having values that uniquely identify each element (n-tuple) of that relation |
| Foreign key | We shall call a domain (or domain combination) of relation R a foreign key if it is not the primary key of R but its elements are values of the primary key of some relation S. |
Operations on relations
| Term | Definition |
| Permutation | A binary relation has an array representation with two columns. Interchanging these columns yields the converse relation. Although it is logically unnecessary to store both relation and some permutation of it, performance considerations could make it advisable. As we can see, the permutation term is at the heart of the indexing process in relational databases. |
| Projection | Suppose now we select certain columns of a relation (striking out the others) and then remove from the resulting array any duplication in the rows. The final array represents a relation which is said to be a projection of the given relation. For table students (id, firstName, lastName, dateOfBirth) when you do SELECT DISTINCT firstName, lastName FROM students, you get a projection of this relation. |
| Join | Suppose we are given two binary relations, which have some domain in common. We can combine these relations to form a ternary relation that preserves all the information in the given relations. This part later will form the basis of the JOIN statement in SQL. |
| Composition | Suppose we are given two relations R, S. T is a composition of R with S if there exists the join of U of R with S such that T = π13(U). Thus, two relations are composable if and only if they are joinable. If you understood all we have here from the first time, then you deserve at least a Ph.D. degree in data science. The topic deserves a dedicated post. Just let me know if you are interested. |
| Restriction | A subset of a relation is a relation. One way in which relation S may act on a relation R to generate a subset of R is through the operation restriction of R by S.  Here R’ is a restriction of R by S. Simply put: SELECT * FROM R WHERE R.p = S.p AND R.j = S.j We take all the records from relation R that include values from relation S. |
Redundancy in Relational Data
Redundancy is a very common topic when it comes to data normalization. Codd defined Strong and Weak redundancy as described below:
| Term | Definition |
| Strong Redundancy | A set of relations is strongly redundant if it contains at least one relation that possesses a projection that is derivable from other projections of relations in the set. |
| Weak Redundancy | The second type of redundancy may exist. In contrast to strong redundancy, it is not characterized by an equation. A collection of relations is weakly redundant if it contains a relation that has a projection that is not derivable from other members but is at all times a projection of some JOIN of other projections of relations in the collection. |
Summary
In this post, we reviewed the rationale standing behind the relational model, went through the terms provided by Codd in the paper: Relation and Relationship, Primary Key, Foreign key, Permutation, Projection, Join, Composition, Restriction, and reviewed Strong and Weak Redundancy.
Edgar Codd’s Relational Data Model is the foundation of modern database management systems. This model uses relations to represent data, and relationships to define the connections between them. By minimizing data redundancy and providing powerful operations on relations, the relational model revolutionized the way data is stored, accessed, and processed. In this article, we explore the history of databases and the fundamental concepts behind the relational model, including relations, relationships, and operations on relations. Join us on a journey to the cradle of database history and discover how Codd’s visionary work transformed the field of computer science.
The paper posted by Codd was a starting point for Relational Database evolution. Today we have multiple products based on the relational concept and the concept after more than fifty years is still actual.
This is my first post on the blog. Don’t forget to share your opinion below, and put comments and suggestions.
Have a great day!
It’s amazing to think how much Edgar Codd’s work has influenced modern database design. Do you think his relational model is still relevant today, or are there newer models that have surpassed it?
Oh wow, Mr. Encyclopedia over here cares so much about history, huh? Listen up compa, I don’t know much about this Edgar Codd guy, but I do know that if you wanna be a good coder, you gotta learn the basics first. Yeah, we got newer models and all that fancy stuff, but you gotta understand how tables, indexes, and triggers work before you start worrying about that. So put down that history book and let’s get coding, cabrón!